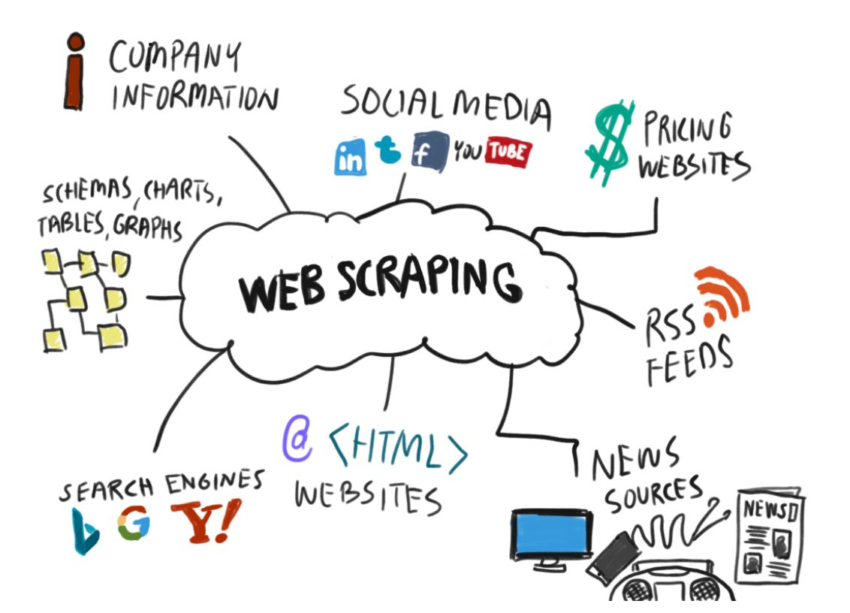
In this article, we will go through the best free web scraping tools available. Web scraping is a process of extracting data from websites. It can be used to extract data from online sources such as social media platforms, e-commerce platforms, and so on.
What is web scraping?
Web scraping is a technique used to extract data from websites. It’s a form of web automation that lets you extract data from websites and save it to a file on your computer.
You can use web scraping to get price data, contact information, product specifications, sports scores, or just about anything else you can find on a website. All you need is the right tools and a little patience. In this article, we’ll show you the best free web scraping tools that will make your life easier.
Why scrape the web?
There are many reasons to scrape the web, but some of the most common include extracting data for analysis, managing large amounts of data, or automating tasks.
Some web scraping tools are free, while others must be purchased. Some are web-based, while others must be installed on your computer. There is a wide range of features and capabilities available in different web scraping tools, so it’s important to choose the one that best fits your needs.
In general, web scraping refers to the process of extracting data from websites. This data can be in the form of text, images, or even videos. It can be used for a variety of purposes, including research, marketing, and even personal entertainment.
What are the best free web scraping tools?
Web scraping is a technique for extracting data from websites. It can be used to extract data from websites that don’t have APIs, or from sites that strictly forbid access to their data.
There are a number of free web scraping tools available, but some are better than others. The three best free web scraping tools are:
-Scrapy: An open source web scraping framework written in Python.
-BeautifulSoup: A library for parsing HTML and XML documents.
-Selenium: A tool for automating web browsers.
Octoparse
Whether you’re a data scientist, researcher, or somebody who needs to collect data for business purposes, web scraping is a skill you should have in your toolkit. Web scraping is a method of extracting data from websites. It’s a handy skill to know for anybody who wants to gather data that’s not easily downloadable. Common use cases for web scraping include extracting data for lead generation, competitive analysis, market research, and price comparison.
What is Octoparse?
Octoparse is a free client-side Windows web scraping software that turns unstructured or semi-structured data from websites into structured data sets, making it easy to get the data you need. Octoparse can handle both static and dynamic websites, with intelligent field recognition that can adapt to changes on the website pages.
With Octoparse, you can scrape data behind login forms, infinite scroll, pop-ups, and the other challenges that you may encounter when trying to harvest data from modern websites. The software also has built-in IP rotation and CAPTCHA solving that allows you to scrape even the most stubborn websites without being blocked.
How does Octoparse work?
Octoparse is a web scraping tool that enables you to scrape data from websites and save it into various formats (Excel, CSV, JSON, etc.). It can handle both static and dynamic websites. Octoparse simulates human browsing behavior to extract data automatically. You don’t need to write any code or have any technical background. Just enter the URL of the website you want to scrape, and Octoparse will do the rest.
What are the features of Octoparse?
Octoparse is a free web scraping tool that enables users to extract data from websites with just a few clicks. It offers a point-and-click interface that allows even those with no programming experience to scrape the web. Octoparse also comes with an intuitive UI that makes it easy to use.
Some of the features of Octoparse include:
– Point and click interface – Octoparse’s point and click interface makes it easy to scrape data from websites, even for those with no programming experience.
– Intuitive UI – Octoparse’s intuitive UI makes it easy to use, even for those with no programming experience.
– Extract data from websites – Octoparse enables users to extract data from websites with just a few clicks.
– Supports multiple file formats – Octoparse supports multiple file formats, making it easy to export your data in the format of your choice.
Scrapy
What is Scrapy?
Scrapy is a free web scraping tool that enables you to extract data from websites in an automated fashion. It is one of the most popular web scraping tools available, and has been used for data extraction by companies such as Google, Microsoft, and Yahoo. Scrapy is written in Python, and can be used to scrape data from websites that are written in any language.
How does Scrapy work?
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
Scrapy is written in Python.
What are the features of Scrapy?
Scrapy is a free and open-source web-crawling framework written in Python.
Scrapy is a fast, efficient, and highly extensible web crawling and web scraping framework. It takes care of all the low-level details such as handling proxy servers, cookies, redirects, etc.
BeautifulSoup
What is BeautifulSoup?
BeautifulSoup is a python library that is used for web scraping. It makes it easy to find and extract data from HTML files. BeautifulSoup is free and open source software, so you can use it for any purpose you want.
There are two versions of BeautifulSoup,BeautifulSoup 4 (for Python 2) and BeautifulSoup 3 (for Python 3). BeautifulSoup 4 is the latest version of BeautifulSoup.
How does BeautifulSoup work?
BeautifulSoup is a Python library that is used for web scraping. It parses HTML documents and creates a tree structure from them that can be used to easily extract data from HTML. BeautifulSoup is not restricted to only extracting data, it can also be used to modify and replace data in an HTML document.
What are the features of BeautifulSoup?
BeautifulSoup is a Python library for parsing HTML and XML documents. It offers a very simple interface, which makes it easy to use for beginners, and it also has advanced features for more experienced users.
Some of the features of BeautifulSoup include:
-Support for multiple browsers, including Firefox, Chrome, Safari, and IE.
-Can parse HTML documents from files or strings.
-Supports both well-formed and malformed HTML documents.
-Can find all tags on a page, or only specific tags.
-Can search tags by ID, class, or attribute value.
-Can replace tags or contents of tags.
Conclusion
In conclusion, these are some of the best free web scraping tools available today. If you need to scrape data from a website, one of these tools will definitely be of help.
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript
JavaScript